<style>
#doc>div, #doc>p, #doc>ul {
text-align: justify;
}
</style>
<center>
Machine Learning - Introduction et premier algorithme
===
</center>
## Introduction
Vous êtes-vous déjà demandés comment fonctionnent les détecteurs de visages ou de symboles sur des photos ? Les systèmes de recommandation de Deezer, Spotify et YouTube ? Les filtreurs de spam sur votre boîte mail ? Tous ces systèmes font partie des innombrables applications du machine learning, branche de l'intelligence artificielle qui étudie comment des algorithmes peuvent apprendre en étudiant des exemples et en devinant par eux-même les paramètres pertinents du problème. DaTA vous propose un ensemble de tutoriels pour comprendre la théorie derrière cette science et apprendre à la mettre en pratique. Nous utiliserons Python comme langage de référence pour la pratique, car associé aux librairies Numpy, Pandas, Scikit-Learn et Keras, il fournit un outil extrêmement puissant de machine learning.
Ce premier tuto permet d'introduire le vocabulaire du domaine, d'en poser les bases mathématiques, et d'étudier un premier algorithme simple.
## Qu'est-ce qu'un problème de machine learning ?
Il existe deux grandes façons d'aborder un problème d'intelligence artificielle : la française, héritée de Descartes, rationnelle et déductive, et l'anglaise, inspirée de l'empirisme de Hume et inductive. Pour traiter par exemple le problème de reconnaissance d'une patate ou d'une courgette sur une image, le Français cherchera les caractéristiques des deux légumes (couleur, forme, etc.) et écrira un algorithme de type :
```bash
SI une partie de notre image est verte sur une certaine longueur
Retourner "courgette"
SINON SI une partie de notre image est un rond jaune
Retourner "patate"
SINON
Retourner "autre"
```
Cette méthode peut marcher pour des classifications simples, faciles à traiter à la main, et dont un humain peut facilement extraire des caractéristiques systématiques. Mais dès que le Français en aura marre de manger des patates et des courgettes et souhaitera séparer les choux-fleurs des brocolis, il devra réécrire totalement son algorithme !
L'Anglais, lui, a une méthode totalement différente pour résoudre le problème. Il va créer un algorithme qui prend en entrée des milliers d'images dont il connaît la catégorie : patate ou courgette. Cet algorithme va analyser la corrélation qu'il y a entre les images et leur catégorie et en déduire de lui-même les caractéristiques importantes. Lorsqu'on lui donnera une nouvelle image, le programme la comparera aux images qu'il a apprises précédemment pour en déduire statistiquement s'il a à faire une solanacée ou une cucurbitacées. C'est ce qu'on appelle le machine learning.
:::info
En réalité, l'intelligence artificielle est depuis ses débuts (années 1940-50) très largement dominée par le machine learning, qui constitue sa seule branche généralisable. Ses fondateurs sont ainsi très majoritairement anglo-saxons (on peut citer Rosenblatt, McCulloch et Pitts, inventeurs des réseaux de neurones), mais on trouve également quelques Russes (comme Vapnik et Chervonenkis), ceux-ci étant particulièrement réputés en statistiques.
:::
## Les différents types de machine learning
### Apprentissage supervisé
L'apprentissage supervisé (_supervised learning_ en anglais) est certainement la forme de machine learning la plus répandue. Elle consiste à entraîner le programme sur des exemples dont on connaît la catégorie (c'est à cette connaissance qu'elle doit le nom "supervisé"). Il en existe deux types :
#### Classification
<div style="text-align:center">
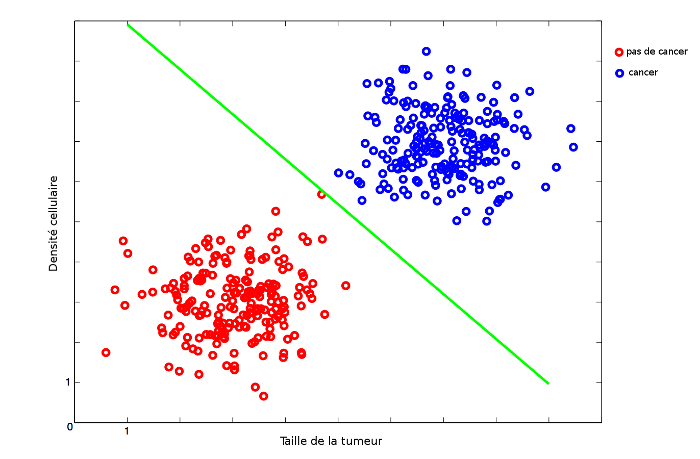
</div>
La classification consiste à déterminer la catégorie d'un objet possédant certaines caractéristiques. Par exemple, prédire si une personne possédant une tumeur est atteinte d'un cancer ou non en fonction de la taille de sa tumeur et de la densité de cellules dans un organe donné. Ainsi, dans le graphique ci-dessus, chaque point représente une personne différente. Elle est placé en fonction de ses caractéristiques. Introduisons maintenant un peu de vocabulaire :
* Classe (également appelée label ou target) : désigne la catégorie (par exemple patate ou courgette, cancer ou pas cancer, etc.). La seule condition sur la classe est qu'elle prenne un nombre fini et discret de valeur.
* Feature : caractéristique. Dans l'exemple du cancer, on n'a pris en compte que deux features (taille de la tumeur et densité cellulaire), mais on pourrait imaginer prendre en compte l'ensemble du génome dans la classification, ce qui conduirait à analyser plusieurs millions de features. Le nombre de features détermine la dimension de l'espace de départ.
* Sample : vecteur de l'espace des features. Dans l'exemple du cancer, un sample représente une personne. Le nombre de samples est ainsi le nombre de points dans le graphe.
* Dataset : base de donnée de samples.
Ainsi, un problème de classification consiste à prédire la classe d'un sample en fonction de ses features, en analysant un dataset. Stylé, n'est-ce pas ?
#### Régression
<div style="text-align:center">
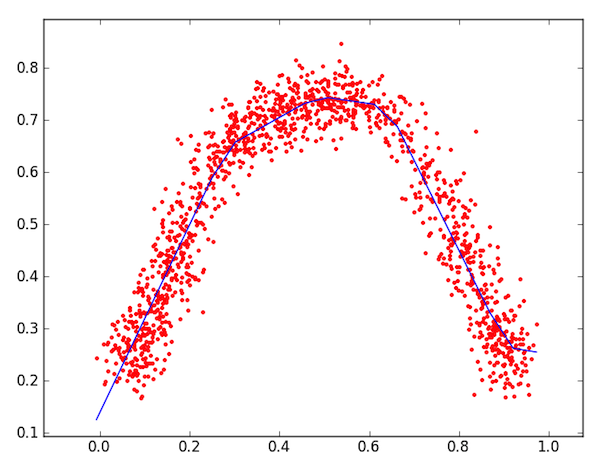
</div>
Le deuxième type de problème supervisé est la régression. La seule différence avec la classification est que la target est continue. Il consiste donc à prédire la valeur associé à un sample en fonction de ses features. Dans l'exemple ci-dessus, l'espace des features est à 1 dimension (il n'y a qu'une caractéristique, en abscisse) et l'axe des ordonnées représente la target. Ainsi, la fameuse régression linéaire utilisée en physique depuis votre tendre enfance est en réalité un problème de machine learning.
### Apprentissage non supervisé
<div style="text-align:center">

</div>
L'apprentissage non supervisé (_unsupervised learning_ en anglais) consiste à caractériser des samples sans connaître les targets. Dans le graphique ci-dessus, un algorithme non supervisé permettra d'établir qu'il existe quatre catégories distinctes, mais ne pourra pas en prédire les classes. Un exemple d'apprentissage non supervisé est [K-means](https://fr.wikipedia.org/wiki/K-moyennes), qui permet de réaliser les nuages de points ci-dessus
### Apprentissage par renforcement
Le dernier grand type d'apprentissage est le [reinforcement learning](https://fr.wikipedia.org/wiki/Apprentissage_par_renforcement), utilisé notamment en théorie des jeux. Il permet à un individu placé dans un certain environnement, pouvant effectuer des actions et obtenir des récompenses, d'optimiser son gain. Chaque expérience faite par l'individu lui permet de mieux connaître son environnement. Par exemple, apprendre à une IA d'échec à effectuer les meilleurs actions pour maximiser la probabilité de gagner peut être résolu par reinforcement learning. L'algorithme de Google [AlphaGo](https://fr.wikipedia.org/wiki/AlphaGo) qui a permis en 2016 de battre le meilleur joueur du monde en Go utilise principalement des techniques de reinforcement learning
## Mathématisation d'un problème
Nous considérons à partir de maintenant que l'on cherche à résoudre un problème d'apprentissage supervisé. Les autres types d'apprentissage seront étudiés dans d'autres tutoriels.
Étudier un problème d'apprentissage supervisé consiste à se donner :
* Un ensemble d'apprentissage de $N$ vecteurs $x_i$ à $M$ dimensions. Chaque vecteur représente un sample, et ses coordonnées représentent les features. $N$ est ainsi le nombre de samples, et $M$ le nombre de features (la dimension de l'espace). En mettant ces vecteurs en lignes, on obtient une matrice $N\times M$ que l'on appelera $X_{train}$, chaque ligne représentant un sample et chaque colonne une feature
* Un vecteur de labels $Y_{train}$ à $N$ dimensions. La composante $i$ représente le label du sample $x_i$ (que ce soit une classe ou une valeur numérique en cas de régression)
* Une matrice $X_{test}$, semblable à $X_{train}$ mais constitué de nouveaux samples dont on cherche à prédire le label.
Ainsi, tout algorithme de machine learning se met sous la forme `Y_pred = predict(X_train, Y_train, X_test)`
## Un premier algorithme simple : la méthode des plus proches voisins
Il existe un très grand nombre d'algorithmes de machine learning, plus ou moins efficaces selon le problème. Le choix de tel ou tel algorithme pour résoudre un problème concret est en général assez expérimental, et les programmes de machine learning les plus performants sont en général une combinaison de différents algorithmes. Concentrons-nous pour l'instant sur un des algorithmes les plus simples d'apprentissage supervisé, qui possède une version pour la classification et une version pour la régression : la méthodes des K plus proches voisins (_K-nearest-neighboors_, abrégé K-NN).
### K-NN pour la classification
<div style="text-align:center">

</div>
Lorsqu'on cherche à déterminer la classe d'un nouveau point (le carré bleu sur la figure), étant donné un ensemble de samples d'entraînement (les croix et les ronds), l'idée la plus intuitive est de considérer le plus proche voisin de ce point.
<div style="text-align:center">

</div>
Ici, un simple Nearest Neighbors prédit que le point test appartient à la classe "rond", ce qui paraît être effectivement le cas. Cependant, dans la vraie vie, les datasets ont souvent des classes bien moins séparés, comme le montre l'exemple ci-dessous :
<div style="text-align:center">

</div>
Ici, le point le plus proche du point bleu appartient à la classe "vert". Or, on peut voir qu'il est en réalité dans le domaine rouge. Ainsi, il peut être intéressant de ne pas considérer seulement le plus proche voisin, mais les K plus proches voisins, K étant un paramètre de l'algorithme. Le point test appartient alors à la classe majoritaire dans le voisinage. Par exemple, en appliquant ici un 4-NN, on prédit bien la classe rouge pour le point test.
<div style="text-align:center">

</div>
### K-NN pour la régression
Le principe pour la régression est quasiment le même que pour la classification, la moyenne remplaçant le vote. Étudions l'exemple suivant, où le but est de prédire l'ordonnée du point vert :
<div style="text-align:center">

</div>
:::danger
Attention, contrairement à l'exemple précédent de classification qui était à deux dimensions, l'espace considéré est ici à une dimension. L'unique feature est représenté sur l'axe des abscisses, tandis que l'axe des ordonnées représente la target.
:::
On considère ici les 6 plus proches voisins en terme d'abscisse, et on effectue la moyenne des ordonnées :
<div style="text-align:center">

</div>
### Analyse de l'algorithme
La plupart des algorithmes d'apprentissage supervisé se décomposent en deux étapes : une étape d'entraînement qui est souvent très longue et nécessite beaucoup de calculs afin d'établir un modèle, et une étape de prédiction, souvent instantané, qui ne fait qu'appliquer le modèle. L'algorithme des plus proches voisins est en cela atypique dans le monde du supervised learning, en ce qu'il n'y a qu'une étape de prédiction, assez longue. En effet, pour chaque point de l'ensemble de test, il faut établir sa distance avec chaque point de l'ensemble d'entraînement et prendre les K plus petites valeurs. Calculer une distance euclidienne entre deux vecteurs à M dimensions (M est la dimension de l'espace des features) demande m opérations. Chaque prédiction demande ainsi $O(N\times M)$ opérations (n étant le nombre de samples).
#### Résultats expérimentaux
Malgré sa simplicité, l'algorithme des plus proches voisins donnent de très bons résultats dans beaucoup de cas. Comme le montre [ce comparatif des algorithmes de machine learning sur la base de donnée MNIST](http://yann.lecun.com/exdb/mnist/), il est possible d'obtenir moins de 5% d'erreurs dans la reconnaissance de caractères écrits à la mains sur des images (en considérant pour chaque image le simple vecteur constitué de la valeur des pixels en noir et blanc)
## Conclusion
Nous avons appris à reconnaître un problème de machine learning, à l'écrire sous forme matriciel et à le résoudre avec la méthode des plus proches voisins. Cette méthode est un algorithme parmi tant d'autres, qui possède la principale propriété de ne pas nécessiter d'entraînement, mais seulement une longue prédiction. Dans les prochains tutoriels, nous étudieront d'autres algorithmes de machine learning, notamment les réseaux de neurones, dont vous avez peut-être déjà entendu parler. Nous verront également comment résoudre des problèmes pratiques avec les librairies Python de ML.
## Liens pour approfondir
[Kaggle](https://www.kaggle.com/) : site de compétitions de machine learning, donnant accès à un grand nombre de bases de données et d'exercices pour progresser dans le domaine
[MOOC sur le machine learning](https://fr.coursera.org/learn/machine-learning/) : MOOC donné par Andrew Ng, célèbre professeur de machine learning à Stanford. Très facile à suivre et adapté à tous les niveaux.
[Neural networks and deep learning](http://neuralnetworksanddeeplearning.com/chap1.html) : ensemble de tutoriels sur les réseaux de neurones, qui en donnent une vision à la fois intuitive et rigoureuse. C'est le site le plus complet que je connaisse à ce sujet.